SHA-1消息摘要算法实验讲解
SHA-1消息摘要算法实验讲解
本文章用于展示现代密码学实验三:消息摘要算法 SHA-1 的实现。页面内容分为三部分:第一部分说明 SHA-1 的背景与算法流程,第二部分对应分析的 C/C++ 实验代码,第三部分通过浏览器中的 JavaScript 交互演示填充、消息扩展、摘要计算和雪崩效应。
一、Hash 函数背景
1. Hash 函数的作用
Hash 函数可以把任意长度的输入映射为固定长度的输出。在密码学中,Hash 函数常用于完整性校验、数字签名、消息认证码、文件指纹和口令存储等场景。
对一个文件计算 SHA-1 摘要后,只要文件中任意一个字节发生变化,最终摘要就会发生明显变化。接收方可以重新计算摘要并对比,从而判断数据是否被修改。
2. Hash 函数的基本性质
一个密码学 Hash 函数通常希望满足以下性质:
| 性质 | 含义 |
|---|---|
| 确定性 | 相同输入一定得到相同摘要 |
| 固定长度输出 | 不论输入多长,输出长度固定 |
| 单向性 | 从摘要难以反推出原文 |
| 抗弱碰撞 | 给定一个消息,难以找到另一个消息具有相同摘要 |
| 抗强碰撞 | 难以找到任意两个不同消息具有相同摘要 |
| 雪崩效应 | 输入发生微小变化,输出应出现明显变化 |
SHA-1 输出长度为 160 bit,也就是 20 字节,通常写成 40 个十六进制字符。
3. SHA-1 的安全性现状
SHA-1 曾经被广泛用于数字签名、证书、版本控制和文件校验等场景。但随着碰撞攻击研究的发展,SHA-1 已经不再适合用于高安全要求的数字签名和证书体系。目前更推荐使用 SHA-256、SHA-3 或我国商用密码标准中的 SM3。
二、SHA-1 算法总览
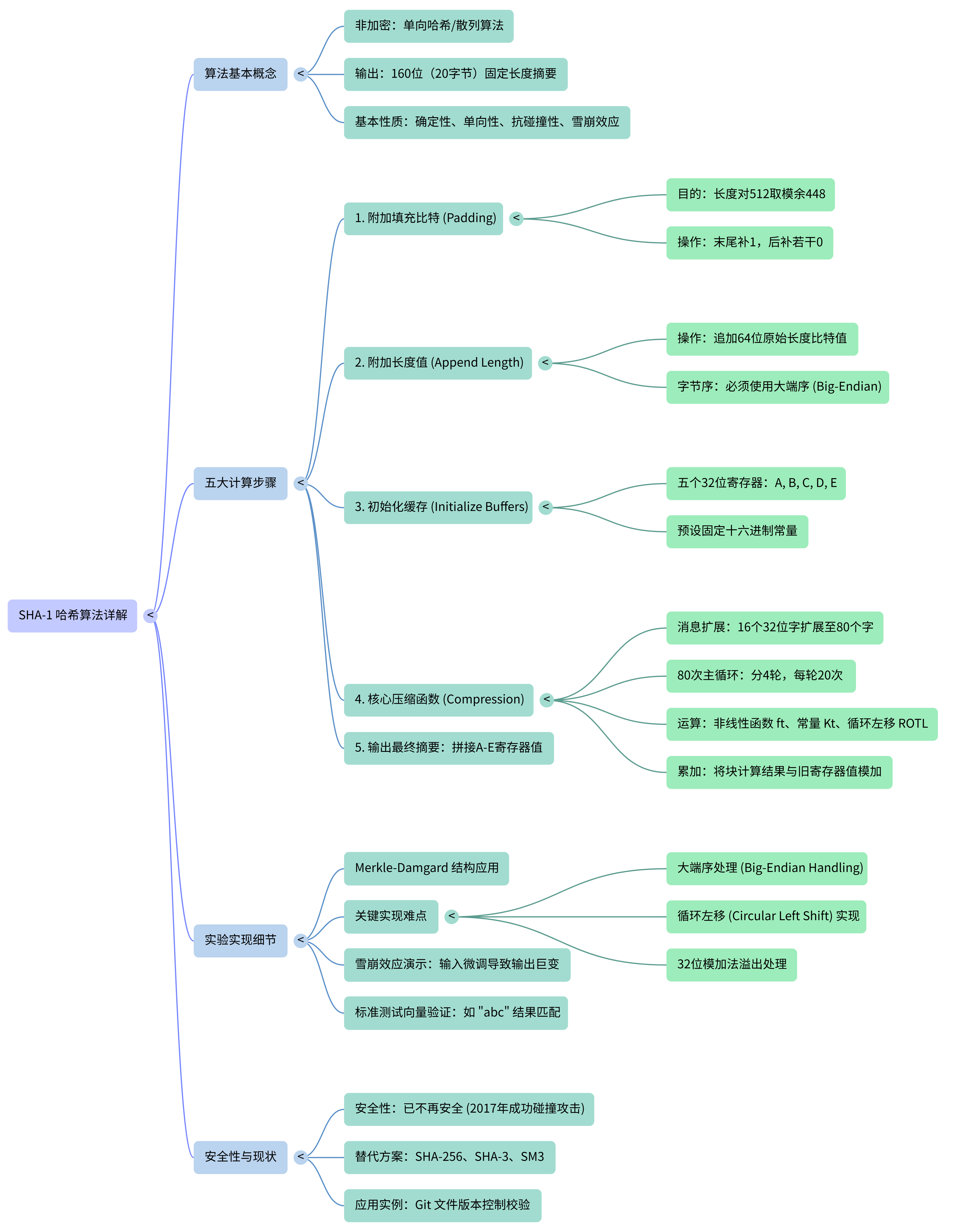
这一部分先从全局视角看 SHA-1 的处理流程,帮助建立整体印象。具体的算法原理放在第三部分展开,代码如何实现这些步骤放在第四部分说明。
SHA-1 的整体流程可以概括为:
1 | 任意长度消息 |
1. 输入与输出
SHA-1 的输入是任意长度的二进制消息,输出固定为 160 bit。最终的 160 bit 摘要由 5 个 32 bit 状态字拼接而成:
$$
\text{Output} = H_0 \parallel H_1 \parallel H_2 \parallel H_3 \parallel H_4
$$
也就是说,不论输入消息有多长,最终都会被压缩成 20 字节,也就是 40 个十六进制字符。
2. 整体处理阶段
如果把 SHA-1 当成一条流水线来看,它主要包含四个阶段:
| 阶段 | 作用 |
|---|---|
| 消息填充 | 把原始消息补齐到 512 bit 的整数倍,并记录原始长度 |
| 分组与拆字 | 将每个 512 bit 分组拆成 16 个 32 bit 字 |
| 消息扩展 | 由前 16 个字扩展出 80 个字 |
| 压缩迭代 | 对每个分组执行 80 轮运算,最终得到 160 bit 摘要 |
三、SHA-1 详细流程解析
第二部分给出的是总览,这一部分开始进入算法细节。这里会把 SHA-1 的初始化、填充、消息扩展和压缩过程放在同一条理论链路里讲清楚。
1. 初始状态
SHA-1 在开始处理消息之前,会先设置 5 个固定的 32 bit 初始常量:
$$\begin{array}{rcl} H_0 &=& 0x67452301 \cr H_1 &=& 0xEFCDAB89 \cr H_2 &=& 0x98BADCFE \cr H_3 &=& 0x10325476 \cr H_4 &=& 0xC3D2E1F0 \end{array}$$
它们共同组成当前的 Hash 状态。后续每处理完一个 512 bit 分组,这 5 个状态字都会被更新一次,直到所有分组处理完毕为止。
2. 消息填充
SHA-1 在处理消息前必须先进行填充。填充的目标是让最终消息长度变成 512 bit 的整数倍,并且在最后 64 bit 记录原始消息长度。
填充规则如下:
- 在消息末尾追加一个
1bit。按字节表示就是追加0x80。 - 继续补若干个
0bit,使当前长度满足448 mod 512。 - 最后追加 64 bit 原始消息长度,采用大端序。
如果以字节为单位,标准公式如下,这里的 56 是因为每个分组共 64 字节,最后 8 字节要保留给原始长度,因此前面内容需要停在第 56 字节。
$$
\text{pad} = (56 - (input_len + 1) \bmod 64 + 64) \bmod 64
$$
3. 分组与字拆分
填充后的消息长度一定是 512 bit 的整数倍。每个 512 bit 分组等于 64 字节。每个分组再拆成 16 个 32 bit 字。由于SHA-1 使用大端序,因此连续 4 个字节组合为一个 32 bit 字时,高位字节在前。
$$
W[0], W[1], \ldots, W[15]
$$
4. 消息扩展
前 16 个字来自原始分组,后 64 个字由前面的字带入到公式中扩展得到。这一步的作用是让原始分组中的每一部分逐渐扩散到后续压缩轮次中,增强混淆和扩散效果。
$$
W_t = ROTL^1(W_{t-3} \oplus W_{t-8} \oplus W_{t-14} \oplus W_{t-16})
$$
5. 80 轮压缩
每个 512 bit 分组都会进入一次 80 轮压缩。压缩开始前,先把当前 Hash 状态复制到 5 个工作变量:
$$\begin{array}{rcl} A &=& H_0 \cr B &=& H_1 \cr C &=& H_2 \cr D &=& H_3 \cr E &=& H_4 \end{array}$$
SHA-1 的 80 轮压缩被分成 4 个阶段,每个阶段 20 轮。不同阶段使用不同的逻辑函数和常量。
| 轮数范围 | 逻辑函数 f(B,C,D) |
常量 K |
|---|---|---|
| 0-19 | (B & C) | (~B & D) |
0x5A827999 |
| 20-39 | B ^ C ^ D |
0x6ED9EBA1 |
| 40-59 | (B & C) | (B & D) | (C & D) |
0x8F1BBCDC |
| 60-79 | B ^ C ^ D |
0xCA62C1D6 |
每一轮的核心公式如下,其中 ROTLn(x) 表示对 32 bit 整数 x 进行循环左移 n 位。
$$
TEMP = (A \ll 5) + f_t(B, C, D) + E + W_t + K_t
$$
$$\begin{array}{rcl} E &=& D \cr D &=& C \cr C &=& ROTL^{30}(B) \cr B &=& A \cr A &=& TEMP \end{array}$$
80 轮结束后,再把工作变量加回状态,这里的加法是 32 bit 模加法,溢出部分丢弃。
$$\begin{array}{rcl} H_0 &=& H_0 + A \cr H_1 &=& H_1 + B \cr H_2 &=& H_2 + C \cr H_3 &=& H_3 + D \cr H_4 &=& H_4 + E \end{array}$$
四、C/C++ 实现解析
我自己写的C/C++代码调用链如下:
1 | Encrypt_SHA1() |
1. Encrypt_SHA1():整体摘要计算入口
1 | void Encrypt_SHA1(const unsigned char* plaintext, int len, unsigned char chipertext[20]) { |
Encrypt_SHA1() 是整个实现的总控函数,主要负责把第三部分中的几步理论流程按顺序串起来。
这个函数内部主要做了:
- 初始化
H[5],也就是第三部分介绍过的 5 个初始常量。 - 调用
Full(plaintext, len, filled_plaintext),把原始消息填充成 64 字节的整数倍。 - 按 64 字节为一组循环调用
Every_block(),让每个分组依次完成扩展和压缩。 - 最后把
H[0]到H[4]按大端序拆成 20 个字节,写入chipertext。
因此,阅读代码时可以把 Encrypt_SHA1() 看成“调度中心”,它本身不负责具体的位运算细节,而是负责组织整个处理流程。
2. Full():把第三部分的填充规则落到代码里
1 | int Full(const unsigned char* input, int input_len, unsigned char* output) { |
memcpy(output, input, input_len) 先把原始消息复制到输出缓冲区,然后 output[input_len] = 0x80 追加二进制的 10000000,也就是标准中的“先补一个 1 bit”。
代码中的int pad = (119 - (input_len % 64)) % 64;对应的就是第三部分中的填充公式。这与第三部分给出的标准公式是等价的。因为程序已经把 0x80 单独追加了,所以这里的 pad 表示在 0x80 后面还要补多少个 0x00,使得长度字段写入前的位置刚好落在第 56 字节。
$$
\text{pad} = (56 - (input_len + 1) \bmod 64 + 64) \bmod 64
$$
最后这段循环负责把原始消息长度 input_len * 8 写入最后 8 字节,并按照大端序存放。执行完 Full() 后,Encrypt_SHA1() 就得到了一个可以直接按分组处理的新消息。
1 | for (int j = 0; j < 8; j++) { |
3. Every_block():实现单个分组的扩展与压缩
Encrypt_SHA1() 拿到填充后的消息后,会每隔 64 字节调用一次 Every_block()。这个函数负责完成第三部分中的“字拆分、消息扩展、80 轮压缩、结果回写”。
先看函数开头:
1 | void Every_block(const unsigned char* block, unsigned int H[5]) { |
这里做了三件准备工作:
- 定义
w[80],用于保存当前分组对应的 80 个消息字。 - 把
H[0]到H[4]复制到工作变量A到E,后面的 80 轮迭代都围绕这 5 个变量展开。 - 定义 4 个阶段常量
K[4],分别对应 SHA-1 的四段轮函数。
3.1 装载 W[0] 到 W[15]
前 16 个字直接来自当前 512 bit 分组:
1 | for (int i = 0; i < 16; i++) { |
这段代码每次读取连续 4 个字节,并把它们拼成一个 32 bit 无符号整数。由于 SHA-1 使用大端序,所以 block[4 * i] 放在最高 8 位,block[4 * i + 3] 放在最低 8 位。
3.2 扩展 W[16] 到 W[79]
前 16 个字准备好之后,代码继续生成后面的 64 个扩展字,对应第三部分中的消息扩展公式:
$$
W_t = ROTL^1(W_{t-3} \oplus W_{t-8} \oplus W_{t-14} \oplus W_{t-16})
$$
1 | for (int t = 16;t < 80;t++) { |
这里本质上是在手动实现第三部分中的 ROTL1(...)。因为普通左移会把最高位丢掉,所以代码又把结果右移 31 位,将原来的最高位补回最低位。
3.3 switch-case 完成四阶段 80 轮压缩
消息扩展完成以后,代码进入 80 轮循环。它对应的核心轮公式仍然是:
$$
TEMP = (A \ll 5) + f_t(B, C, D) + E + W_t + K_t
$$
用 switch (j / 20) 把 80 轮切成 4 个阶段,每 20 轮进入一个 case,分别对应第三部分中的四组逻辑函数和常量。
1 | for (int j = 0;j < 80;j++) { |
无论进入哪一个 case,每轮结束后都会执行同样的状态更新:
1 | E = D; |
这里 ((A << 5) | (A >> 27)) 表示 ROTL5(A),((B << 30) | (B >> 2)) 表示 ROTL30(B)。这种写法把 80 轮压缩统一放在一个循环中,比拆成四段重复代码更紧凑,也更容易看出“阶段不同,但更新框架一致”。
3.4 把本分组结果加回 H[5]
80 轮结束后,还要把工作变量累加回全局状态:
1 | H[0] += A; |
这一步对应的正是第三部分中“80 轮结束后再把工作变量加回状态”的理论步骤。A 到 E 是当前分组的临时结果,而 H[0] 到 H[4] 才是跨分组持续传递的链接值。
因此,从程序结构上看,Encrypt_SHA1() 负责组织流程,Full() 负责落实填充规则,Every_block() 负责完成单分组的扩展与压缩,三者合起来就把第三部分的算法流程完整实现了出来。
五、交互演示
在线计算 SHA-1
160 bit / 40 hex chars实验数据快速验证
点击样例自动计算并对比报告结果填充过程展示
对应 C++ 中的 Full()点击“查看填充”后显示。
消息扩展展示
展示第一个 512 bit 分组的 W[0] 到 W[79]雪崩效应演示
只改动一个字符,观察摘要变化六、实验结果
| 序号 | 明文 | SHA-1 |
|---|---|---|
| 1 | iscbupt |
664dc9f017dc1aee4a4366bcfb8511afc89f9430 |
| 2 | seven |
a00bbe560e6b0f5263e3e6cba4ff3fb9a6fe9ef0 |
| 3 | Hainan University |
7f6901c5d21108d6e457263f6ba1271f1fd8154c |
| 4 | This is a secret |
71800b4c97bcccbe286bcde42701be53f4852de8 |
| 5 | Symmetric Cryptosystem and Public Key Cryptosystem |
d86c3f866c88d544e75391a7cb15be5b8f6a3709 |
| 6 | The proposed scheme is not only able to provide mutual authentication without communication with the trusted third party, but also fulfills various security features, such as user anonymity, forward secrecy, etc. |
9a1a297fa737b459e32f6a336798ecab24bfb1f6 |




